ElasticSearch 살펴보기 - Query
ES Query 종류
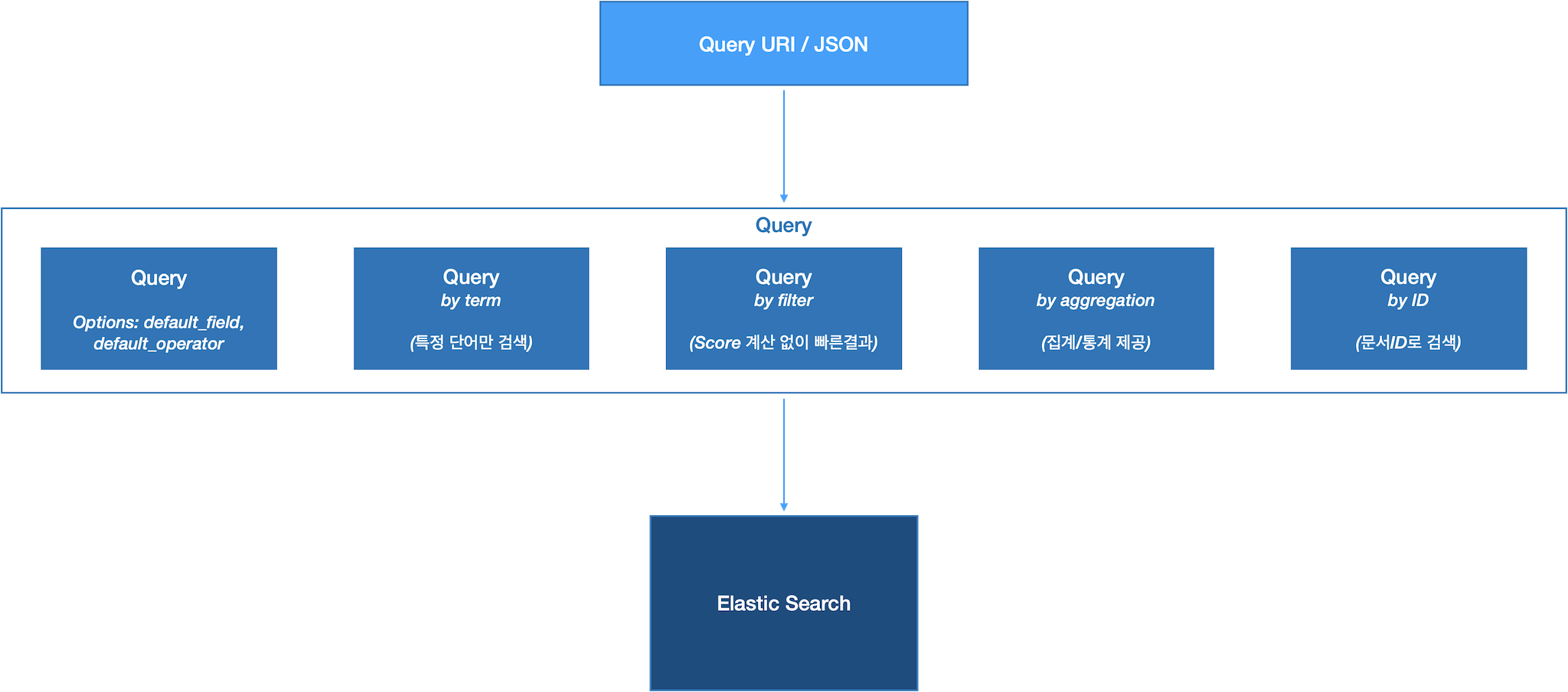
URI 방식 Query
- HTTP GET 방식으로 데이터 조회
- ex.
GET {인덱스명},{인덱스명}/_search(멀티 인덱스 지정 가능) - ex.
GET {인덱스명접두어}*/_search(인덱스 지정에 wildcard 사용 가능)
- ex.
- 검색 옵션은 url param 에 key=value 형태로 지정
| 자주사용하는 url param | |
|---|---|
| q | - 쿼리 - ex. ‘{필드명}:{검색어} AND {필드명}:{검색어}’ |
| df | - 검색할 필드 - 쿼리에 검색 대상 필드가 지정되어있지 않을 경우, 검색하는 필드 |
| analyzer | - 형태소 분석기 |
| analyzer_wildcard | - prefix, wildcard(*) 사용여부 (default: false) |
| default_operator | - 검색 조건 연산자 (default: OR) |
| _source | - 검색 결과에 문서본문 포함여부 (default: true) |
| sort | - 정렬기준 필드 - ex. ‘{필드}:desc,{필드명}:asc’ |
| from | - 검색 시작 offset |
| size | - 검색 결과 개수 |
QueryDSL 방식 Query
- 검색 옵션을 json 형태로 지정
- ex.
GET {인덱스명},{인덱스명}/_search(멀티 인덱스 지정 가능) - ex.
GET {인덱스명접두어}*/_search(인덱스 지정에 wildcard 사용 가능)
POST {인덱스명}/_search
{
"query" : {
"query_string": {
"default_field": "{쿼리에 검색 대상 필드가 지정되어있지 않을 경우, 검색하는 필드}"
"query": "{필드명}:* OR {필드명}:{검색어}"
}
},
"agg" : { ... } // 통계, 집계를 위한 필드
"from": 0, // 검색 시작 offset (from 값 이전의 문서들도 모두 full scan 후 size 만큼 반환한다)
"size": 2, // 검색 결과 개수 (default: 10)
"timeout: 1m", // API 타임아웃 (default: 무한대)
// timeout 시간이 짧으면 timeout 내에 검색된 결과만 반환될 수 있다.
"sort": [ // 정렬 (default: 연관 score 로 정렬)
{
"{필드명}": { "order": "desc"},
"{필드명}": { "order": "asc"}
}
],
"_source": [ // 프로젝션 (default: 문서의 모든 필드가 반환됨)
"{출력대상 필드명}",
"{출력대상 필드명}"
]
}
query context
- 전문검색에 사용
- 분석기로 연관 score 를 계산하여 처리
- 루씬레벨에서 처리 -> 느림
- 디스크 연산 -> 느림
- 결과가 캐싱되지 않음
query filter
- 조건 필터링에 사용
- true/false 로 판단 (score 계산 없음)
- 엘리스틱서치 레벨에서 처리 -> 빠름
- 메모리 연산 -> 빠름
- 엘라스틱서치가 결과를 내부적으로 캐싱함
Query Response
{
“took”: // 쿼리 수행시간
“timed_out”: // 쿼리 timeout 발생 여부
“_shards”: {
“total”: // 쿼리를 요청한 shard 개수
“successful”: // 검색 요청이 성공한 shard 개수
“failed”: // 검색 요청이 실패한 shard 개수
}
“hits”: {
“total”: // 검색어 매치된 문서 전체 개수
“max_score”: // 매칭된 문서 스코어중 최대값
“hits”: [ ] // 각 문서 정보 및 스코어
}
}
Query 유형별 예제
Term 검색
{
"query": {
"term": {
"{필드명}": "{검색어}"
}
},
...
}
범위 검색 (range)
{
"query" : {
"range": {
"{필드명}": {
"gte": "{값}", // gte, gt
"lte": "{값}". // lte, lt
}
}
},
...
}
operator
{
"query" : {
"match": {
"{필드명}": {
"query": "{쿼리}",
"operator": "and" // and, or 사용 가능
}
}
},
...
}
minimum_should_match
{
"query" : {
"match": {
"{필드명}": {
"query": "{쿼리}",
"minimum_should_match": 2
// 문서에 포함되어야할 term 최소 개수
}
}
},
...
}
fuzziness (오차범위 허용, 유사값 검색)
{
"query" : {
"match": {
"{필드명}": {
"query": "{쿼리}",
"fuzziness": 2
// 오차(검색어와 다른 글자) 허용 개수
// 0, 1, 2, auto 지정 가능
}
}
},
...
}
boost (가중치 부여)
{
"query" : {
"match": {
"{필드명}": {
"query": "{쿼리}",
"fields": ["{필드명}^2, "{필드명}"]
// 문서가 일치하는 경우,
// 특정 필드에 계산되는 스코어에 가중치를 부여
}
}
},
...
}
match_all
- 매치되는 모든 문서 검색
{
"query" : {
"match_all": {
"{필드명}": "{검색어}"
}
},
...
}
match
- 형태소 분석 후, 각 Term에 대해 검색
- 각 term 에 대해 지정된 operator 연산으로 검색 (default: OR)
{
"query" : {
"match": {
"{필드명}": "{검색어}"
"operator" : "AND"
}
},
...
}
multi_match
- 여러 필드를 대상으로 검색
{
"query" : {
"multi_match": {
"query": "{검색어}"
"fields": ["{필드명}", "{필드명}"]
}
},
...
}
term
- 형태소 분석하지 않음
- 검색어를 하나의 term 으로 취급
- keyword 타입의 필드를 검색하는 용도
{
"query" : {
"term": {
"{필드명}": "{검색어}"
}
},
...
}
bool
- 여러개의 쿼리 조합 (Compound Query)
- 검색어를 하나의 term 으로 취급
- keyword 타입의 필드를 검색하는 용도
{
"query" : {
"bool": {
"must": [{쿼리}, {쿼리}] // 쿼리간 AND 연산
"must_not": [{쿼리}, {쿼리}] // 쿼리간 AND 연산
"should": [{쿼리}, {쿼리}] // 쿼리간 OR 연산
"filter": [{쿼리}, {쿼리}] // IN 절 처럼 처리
}
},
...
}
query string
- query 로 입력된 문자열을 쿼리 분석기를 사용하여 검색
{
"query" : {
"query_string": {
"default_field": "{필드명}"
"query": "xxx AND yyy"
}
},
...
}
prefix
- prefix 검색
{
"query" : {
"prefix": {
"{필드명}": "{검색어}"
}
},
...
}
exists
- 필드값이 존재하는 문서만 검색
{
"query" : {
"prefix": {
"{필드명}": "{검색어}"
}
},
...
}
wildcard
- 와일드카드 검색 (‘?’, ‘*’)
{
"query" : {
"wildcard": {
"{필드명}": "xxx?"
}
},
...
}
nested
- nested 데이터타입 필드를 검색
{
"nested" : {
"path": "{nested필드 이름}"
"query": { }
},
...
}